發布時間:2025-12-08
2025年12月5日, Neurocomputing期刊在線發表了題為《Towards Biologically Plausible DNN Optimization: Replacing Backpropagation and Loss Functions with a Top-Down Credit Assignment Network》的研究論文。該研究由中國科學院腦科學與智能技術卓越中心、腦認知與類腦智能全國重點實驗室王佐仁研究組王佐仁研究組聯合中國科學院自動化研究所劉成林研究組共同完成。團隊提出了一種全新的類腦學習框架:自頂向下信用分配網絡框架(TDCA,Top-Down Credit Assignment Network),首次利用腦啟發的自頂向下調控網絡,同時替代傳統人工智能中的損失函數與反向傳播算法,在多種任務中實現了更快收斂、更強穩定性和更低計算成本的學習性能。
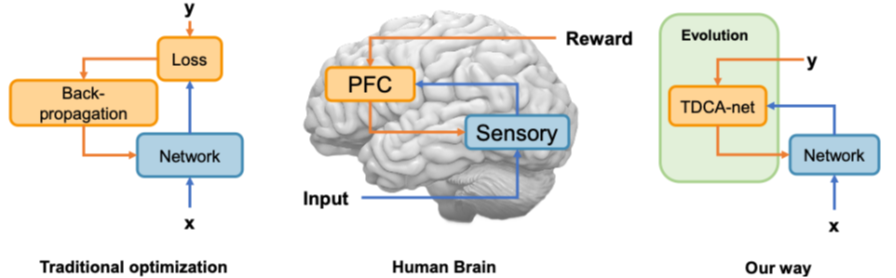
圖1:不同的學習方式比較:傳統人工智能優化,生物大腦以及TDCA網絡方法
長期以來,人工智能的成功依賴“損失函數+ 反向傳播”這一經典訓練范式。然而,一個根本性問題始終存在:人腦并不是通過反向傳播學習的,那么大腦究竟是如何實現高效學習的?如果人工智能也不使用反向傳播,它還能否學會復雜任務?在傳統人工智能中,損失函數由人類顯式設計,誤差信號通過反向傳播逐層精確計算。然而,神經科學研究表明:大腦中并不存在顯式的數值損失函數;也不存在類似反向傳播那樣的精確梯度回傳機制;真正起關鍵作用的,很可能是來自前額葉、扣帶回等高級認知腦區的自頂向下調控信號。這提示,除了傳統“誤差回傳”機制之外,大腦中可能還存在一種內源性的學習調控方式。
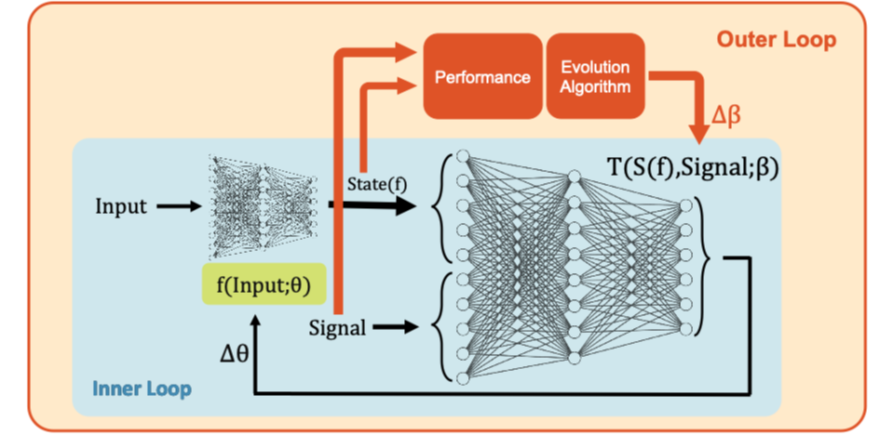
圖2.TDCA網絡整體訓練框架
基于上述神經生物學證據,研究團隊提出了TDCA 自頂向下信用分配網絡框架。該框架由兩個網絡構成:一個負責執行任務的底層任務網絡,以及一個負責生成學習信號的自頂向下調控網絡。不同于傳統方法中“先定義損失函數、再進行反向傳播”,TDCA 框架中:自頂向下網絡直接生成用于更新參數的學習信號,從而整體替代了損失函數和反向傳播。該框架在機制上模擬了大腦中高級腦區對低級腦區的調控作用,使人工神經網絡的學習方式在整體結構上更接近生物大腦。
研究團隊在多個代表性任務中對TDCA 框架進行了系統驗證,包括:非凸函數優化任務(傳統算法易陷入局部最優)、圖像分類任務(MNIST、Fashion-MNIST)、和強化學習任務(CartPole、Pendulum、BipedalWalker、MetaWorld 機械臂控制)。實驗結果表明,TDCA 框架具有以下顯著優勢:收斂更快,更容易跳出局部最優;對初始參數不敏感,穩定性更強;可遷移到新任務,具備良好泛化能力;在多項任務中整體性能優于傳統反向傳播算法及多種生物可實現學習方法。尤其在強化學習和機器人控制任務中,同一個自頂向下網絡可以同時指導多個不同任務的學習,展現出類似大腦“通用學習策略”的特征。
該研究不僅在算法層面實現重要突破,也在類腦人工智能與計算神經科學領域具有深遠意義:為下一代類腦人工智能系統提供全新訓練范式;為低功耗智能芯片提供適配型學習機制;為真實大腦學習機制建模提供新的計算框架;并且為機器人與強化學習系統提供更高效的學習策略。從長遠來看,該工作為構建真正“像大腦一樣學習”的人工智能系統提供了一條全新的技術路徑。
腦智卓越中心特聘研究助理陳建輝博士為該論文的第一作者,王佐仁、劉成林研究員為該論文的共同通訊作者,楊天明研究員對論文做出重要貢獻。該工作得到中國科學院戰略先導專項、科技創新2030重大項目的支持。
 附件下載:
附件下載: 